
Anyone who starts to build an information rich website soon has to start thinking about structuring the pages, and has to start thinking about giving 'information about the information' ('meta' information) on those pages.
Unlike a book, where a table of contents brings you to chapter headings, or a books index, where you look for a single word or phrase within the pages of the book, a web page can instantly transport you to a new subject or explaination on the 'advice' of a 'hypertext linked' word or phrase on the page you are reading.
Pages on a website are able to be read sequentially, like a book, or 'chaotically', by using hypertext links to leap forward, backward and sideways. When we 'read' a body of information 'chaotically', it's easy to lose the thread of where we originally were before we diverged to investigate a certain interesting aspect. This is a problem well known to site designers.
Intellilinker
For small sites the problem can solved
the problem by providing a contents page that gives the broad structure
of the subject and content (typical of any contents page), and then giving
a very short description (albeit subjective and often 'jazzed') of what
you will find on that page (atypical of most contents pages, in the electronic
sense). This helps put the linked pages in context of the subject, and
helps the reader decide if that page is worth visiting.
It is, in effect, a decision making central
hub from which a visitor can launch forays and return.
It is an 'intelligent link' page because
it is logically organised into a (either personally idiosyncratic or formal)
rules-based structure that covers the topic, and it gives enough information
about a hypertext linked word or phrase or subject heading that the visitor
can make intelligent decisions about where to click to, rather than half
guessing.
Ultimately, the usefulness of 'self description'
of information depends on the honesty and objectiveness of the person describing
it. The 'Intellilinker' of most use to a group interested in that subject
area is one that is dispassionate, even if the site authors documents itself.
Hard call.
I coined the word 'Intellilinker' to describe
this electronic contents page. My own proto-example is of a
'passive' intellilinker. That is, the synopses are all laid out to
be read by the viewer and then the viewer mentally orders the contents
into importance according to the viewers interests. Sometimes the descriptions
will convince the viewer that there is nothing there of interest, and they
will depart the site without exploring any link in the intellilinker.
The other problem (beyond objectivity/authority)
with passive intellilinkers - which I quickly realised - is that a single
page becomes large and unweildy as the number of pages grows, obscuring
the overall heirarchic structure becomes difficult to see.
An 'active' intellilinker would be a programme which already 'knew' about the preferences of the viewer, and only show those annotated links that were 'known' by the programme to fit with the viewers interests and world view. If a site offered a body of information on cows (what?!), then a visitor interested in farming would see a custom made intellilinker (possibly drawn from a database) that showed only those links in the body of the work that related to farming cows. If the visitor were interested in food, the link page would show only those links in the body of the work that lead to pages discussing cooking beef. And so on.
Passive or active, the electronic distribution
of 'unbound' pages and cyberspace floating sidebars has meant that knowledge
has to be structured, brief abstracts written about the knowledge, and
'weighted' or given a non-arbitrary value. Only then can knowledge be purposefully,
usefully, and rewardingly accessed.
Intellilinker
defined
All the systems that (1) structure,
(2)abstract, and (3)weight knowledge with the purpose of best meeting the
individual needs of a visitor to an electronic hyperlink based information
dense site can be regarded as 'intellilinkers'.
We think this word, newly coined, is descriptive and useful. We would like to see it in common English useage, rather than as some brand name for a piece of software.
Unless someone has branded this name (and at this date there are no results when 'intellilinker' is put through the major search engines) already, please use this name and make it part of the ever changing English language.
UHIS 1st October 1998
June 2000
The advent of XML, the .NET design of
Microsoft - and others soon to come, no doubt- , and SOAP may coalesce
the 'intellilinker' concept to a universally used, authoratative, moderated,
database/public web server distributed commonplace reality.
August 2000
Look at the partial document reproduced
below. Notice the numbers at the end of each paragraph. These are used
as precise reference points for a chunk of information in the document.
The intention in this instance is that it generates a 'feedback form' for
reader comment or discussion on the specific information in the paragraph
referred to. This commentary can automatically be posted to a discussion
thread which can be further commented on.
This idea can be looked at backwards.
Where documents are deliberately made identifiable either by targeted heading
and subheadings in html, or structurally by description of elements in
xml, authoritative amateurs or experts could identify the location of each
paragraph in any document and critique it. This critique itself could be
described hierarchically, abstracted, and weighted, and exist as an item
retrievable from a database. In this way, a document could be made
that 'logged' its own critiques over time, or, in reverse, critiques could
be found by using keywords, and would in turn lead to documents. So the
'dumb' search engine can become an electronic librarian serving moderated
critiques from keywords, or a Dewey type name heirachy, or a 'subject tree'
in a 'portal' . An intellilinker. Not convinced? Mentally
integrate the concept just mentioned with the concept expressed here.
Published at http://software-carpentry.codesourcery.com/Groupware/report.html
reproduced in part, and with 3 additional 'targets' to subjects
within the document by UHIS on 03/08/00 (Euro date config) under the following
terms:
Copyright (c) 2000 by Jon Udell. This material may be distributed
only subject to the terms and conditions set forth in the Software Carpentry
Open Publication License, which is available at: http://www.software-carpentry.com/openpub-license.html
snip starts
The e-print archive at www.arxiv.org has dramatically changed the way
physicists publicize, and track, the literature in their fields of interest.
Other scientific communities regard the archive as a bold experiment that
will likely influence their own practices. Meanwhile, as the archive continues
to grow in a linear fashion, physicists are starting to face some of the
same information-overload problems that characterize the Web in general.
On a recent Tuesday, there were 36 new papers in just one of the physics
archive's 12 divisions, astrophysics. Can astrophysicists read 36 papers
a day? Should they try? Clearly not. A user of the physics archive will
scan the list, prioritize it based on interest in topic and familiarity
with authors, read selectively, and perhaps transmit items of interest
to colleagues. 112
Every web user engages daily in this process of information refinement.
Many share their results -- that is, URLs with annotations -- in the form
of FYI ("For Your Information") emails. Some also share their results on
personal "links" pages. And a few employ a new tactic called weblogging.
A weblog is really just another kind of annotated links page, typically
in the form of a daily Web diary that filters and reacts to Web information
flow according to personal and/or professional interests. 113
The current weblog craze is, in all likelihood, a passing fad. If you visit Blogger (http://www.blogger.com), a portal site that aggregates over 1000 weblogs, you may conclude that this form of communication has already suffered the same fate that befell the Usenet. One "blogger" (short for "weblogger") recently complained: 114
There was once a hope that the weblog could become a powerful tool for reaching out and connecting with the world. Instead, it has become a powerful tool for self-gratification and self-absorption.
But underlying the weblogging movement are two technological trends -- RSS headline syndication, and pushbutton Web publishing -- that lay the groundwork for better ways to publicize, and monitor, the activities of professional groups. 115
RSS (Rich Site Summary) is an XML vocabulary for representing annotated
links. It debuted in 1999 as the underpinning of my.netscape.com, a service
that aggregates news "channels" that are "broadcast" by its users. Earlier,
in 1995, the PointCast Network (now discontinued) had pioneered this idea.
But publishing a PointCast channel was a complex process. As a result its
news network was exploited mainly by existing publishing organizations,
and ultimately failed. 116
My Netscape made the process radically simpler. Anyone could publish
a channel by posting a simple XML file to a Web server, and registering
that file with the service. Users of the service can then personalize their
My Netscape start pages by selecting from the available channels. Here's
what that start page can look like: 117
Figure 4: Monitoring RSS channels in My Netscape 118
The center column displays channels from major news publishers. The
left and right columns display boutique channels run by smaller publishers,
project teams, and even individuals. In this example, these channels reflect
my own interests -- software and networking. There are as yet few channels
devoted to scientific themes, but such channels easily can, certainly should,
and probably will emerge. 119
If RSS channels could appear only on My Netscape, the mechanism would
be of limited value. But there's more to the story. RSS has caught on as
a standard. Many sites syndicate RSS content, by sourcing channels in XML
format and rendering them as HTML. And there are several sites -- besides
My Netscape -- that aggregate RSS feeds, notably UserLand Software's My
UserLand (http://my.userland.com) and O'Reilly and Associates' Meerkat
(http://meerkat.oreillynet.com). 120
UserLand's principal, Dave Winer, wears two hats. As a journalist, he
has for years published technology news in the form of an email newsletter
and a related website, Scripting News
(http://www.scripting.com). In 1997, Winer began offering Scripting News
in an XML format suitable for syndication. The idea was that, given a regular
and predictable format for headlines and blurbs, other sites wanting to
carry a Scripting News feed could easily syndicate the content -- that
is, scoop up the XML, and retransmit it as HTML tailored to their own presentation
styles. 121
As a software developer, Winer has evolved his product -- called Frontier
-- from a Macintosh scripting language into a cross-platform (Windows/Mac-based)
Internet publishing and content-management system known as Manila. It is,
among other things, a channel-authoring tool. Manila can automatically
make the content that it manages available in RSS format for syndication.
122
The O'Reilly Network's Meerkat is an "open wire service" that demonstrates
the emergent properties of RSS syndication. Meerkat watches channels listed
in two RSS registries -- one at UserLand, one at xmlTree
(http://www.xmltree.com). On the union of these two registries (which are
partly overlapping, partly distinct), Meerkat performs a selection. It
chooses just those "technology/computer/geek" channels relevant to the
O'Reilly Network's audience. Then it categorizes these channels so that
a Meerkat user can make a single selection -- say, Python -- in order to
view headlines and blurbs from a half-dozen Python-related channels. 123
Behind the scenes, the editors and writers at the O'Reilly Network --
which is itself an informational site for software developers and Internet
technologists -- use Meerkat to track their individual beats. They select
interesting items, add additional analysis to them, and republish them
along with the site's original content. In parallel, they maintain Manila
weblogs where, as columnists, they can deliver less formal, and more personal,
summary and analysis. These weblogs, thanks to Manila's automatic syndication,
flow back out onto the RSS wire. See, for example, Edd
Dumbill's weblog (http://weblogs.oreillynet.com/edd/). 124
All this adds up to a new kind of information ecology inhabited by RSS authors, sites that syndicate RSS content, and services that aggregate, select, refine, and republish RSS content. In the most populous niche of this ecology -- the "technology/computer/geek" space occupied by the likes of UserLand and Meerkat -- the publication and assimilation of news is radically simplified and accelerated. News, in this realm, takes on a broader-than-usual meaning. Anything that can be referenced with a URL is fair game. That includes announcements, feature stories, opinions, and analysis published on conventional media sites. But it can equally include entries from weblogs that report on very narrow and specific fields of interest. Typically, such weblogs are themselves aggregators of many sources of information. One of the most intriguing new roles that has emerged is what might be called a list guide. By that I mean a specialist in a field who monitors its mailing list or newsgroup, and draws attention to significant items -- often packaged with a bit of analysis. In this way interested people who lack the time and/or expertise to process the raw feeds can, nevertheless, keep in touch with developments in related, or even distant, disciplines. 125
Although HTML is a far simpler markup language than, say, TeX, today's
Web is biased heavily toward consuming content, and offers little support
for producing it. The Web, in its current incarnation, is a library in
which we read, not a bulletin board on which we scribble. The Internet
application that we do use for scribbling -- endlessly, prolifically --
is email. But while email can (and often does) become Web content, it's
never first-class Web content. 126
Lately there is movement on a number of fronts to reclaim the two-way, read/write architecture that was the Web's original conception. Part of the story is a new protocol called WebDAV (Web-based Distributed Authoring and Versioning, http://www.webdav.org/, also known simply as DAV), which enables client applications to store documents directly on a DAV-aware Web server, lock and unlock the documents, and query or set their properties. DAV-aware servers include Apache (with the mod_dav module), Microsoft's Internet Information Server version 5, and Digital Creations' Zope. DAV-aware clients include the Microsoft Office apps and, more recently, Adobe's Go Live, a Web authoring and content-management tool. 127
You can think of WebDAV, in its current form, as a "better FTP" that integrates directly into applications, making "save to the Web" a pushbutton affair. It supports locking, and deals more powerfully than FTP with moving and copying collections of files. The DAV FAQ notes these additional benefits: 128
Since DAV works over HTTP, you get all the benefits of HTTP that FTP cannot provide. For example: strong authentication, encryption, proxy support, and caching. It is true that you can get some of this through SSH, but the HTTP infrastructure is much more widely deployed than SSH. Further, SSH does not have the wide complement of tools, development libraries, and applications that HTTP does.
FTP is deeply entrenched and still overwhelmingly dominant, but DAV is maturing and will very likely displace FTP over time. Less clear, at this moment, is what will come of the versioning and configuration management features (http://www.webdav.org/deltav/goals/draft-ietf-webdav-version-goals-01.txt) proposed for DAV. 129
Manila's approach to the two-way Web proceeds from the assumption that,
while DAV-enabled writing and content-management tools are desirable, they
are not strictly necessary. The basic browser, backed by conventional Web-server
software, can empower groups to collaborate and to publish their collaborations
on the Web. 130
To that end Manila, among other things, is a Web-based discussion system.
Every story or news item posted to a Manila site can be a launching point
for threaded discussion -- which can occur out in the open, visible to
all site visitors, or privately, visible only to members of the site. 131
Manila supports pushbutton web publishing in a number of ways: 132
Instant startup. UserLand offers a free service -- www.EditThisPage.com -- so that anyone can launch and run a collaborative weblog that publishes news and discussion in some area of interest, and integrates with the RSS news network. You can, of course, buy Manila/Frontier and deploy it on your own Internet or intranet site, but EditThisPage.com delivers instant gratification. 133
Live editing. A site operator can use the Edit link that appears on every page to fetch and modify the page in a browser form. There's limited support for Wiki-like automatic formatting and, in MSIE, a simple interactive formatter helps authors apply styles to selected ranges of text. In general, though, Manila doesn't pretend to be a full-blown Web authoring environment. Its goal is to move the kind of simple writing that we do in email into the realm of managed, and syndicated, websites. 134
Publication workflow. A Manila site embodies a specific groupware protocol -- that of a newspaper or journal. It supports the notion of a managing editor, working with a team of contributing editors, to produce a stream of stories that are developed internally, discussed, edited, and then released to the public. 135
Spontaneous citation. One of the most fundamental acts of Internet
collaboration is the "FYI email" -- a message that cites, or attaches,
an interesting Web document. It's incredibly valuable to be able to do
this spontaneously, as email permits. But there are also some severe drawbacks.
The FYI email targets only the specified recipients. It appears in their
message flow -- too often, as clutter -- and then scrolls off the event
horizon. It doesn't, in general, create a public document that can be found
by other people, at other times, working in different contexts. With Manila,
the impulse behind a spontaneous FYI email can -- using a small helper
application called Manila Express -- be expressed as a spontaneous act
of web publishing. Consider this example: 136
Figure 5: Manila Express 137
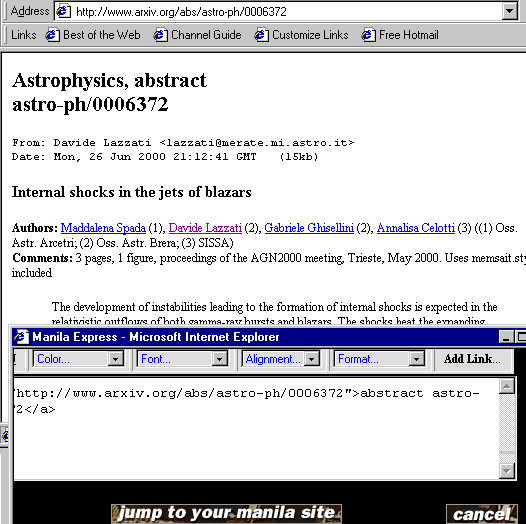
Here, while viewing an astrophysics abstract in MSIE, I've launched Manila Express (from MSIE's right-click-accessible popup menu). It has loaded the URL of the abstract into its editing window, and I've begun to write an annotation for the cited paper. When I click the Post button, the URL-plus-annotation is added to my Manila weblog -- and to its RSS channel. Thus, in a single stroke, I've accomplished three collaborative goals. First, I've alerted anyone who visits my weblog to the existence of this paper, and my explanation of its importance. Second, I've enabled the paper, and my analysis of it, to form the seed of a threaded discussion. Third, I've broadcast my citation-plus-analysis to the RSS network, so that people not directly tuned into my weblog can nevertheless discover this item. How? Let's turn our attention from the realm of RSS authoring and publishing to the realm of RSS aggregation, viewing, and searching. 138
Meerkat is nominally an RSS aggregator and viewer. It fetches RSS channels
from multiple registries, eliminates duplication, and stores the resulting
set of items in a database. Through its Web interface you can query that
database. In this example, Meerkat reports all items for the last 30 days,
from all channels grouped in the SCIENCE category, that mention the term
"black hole": 139
Figure 6: Meerkat 140
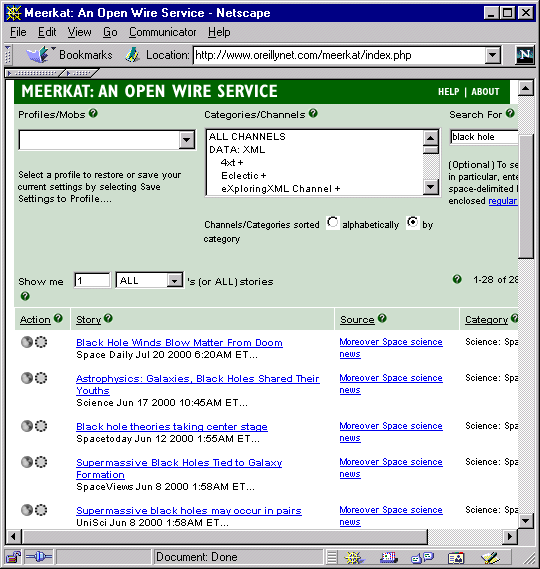
But Meerkat's inventor, Rael Dornfest, has also made it into tool that
simplifies publishing, as well as viewing, sets of RSS items. Registered
users can define two kinds of named collections. A profile is a stored
query. So for example, the Meerkat URL http://meerkat.oreillynet.com/?p=739
names a query that asks: "Show me all the items from Jon Udell's channel."
A mob is an arbitrary collection of items. A user can define such a collection,
give it a name such as "BlackHole," then assign items from any channel
to it by clicking one of the item's circular icons. Like profiles, mobs
are represented by URLs that can be shared in email, or published on websites.
141
For the Meerkat user, managing these stored queries and named collections
is a point-and-click affair. But suppose you want to republish these views
of the RSS news flow? Meerkat supports a number of interfaces that make
it easy to repurpose the content it manages. You can, for example, ask
Meerkat to produce output in the same RSS format that it consumes. In this
mode, Meerkat runs as a pure filter -- one of potentially many phases in
an information-refinement pipeline. This is a crucial point. Applications
and services that both consume and produce XML are, automatically, reusable
components that can be combined and recombined to create novel effects.
There is not likely to be a single "killer app" in the realm of Internet
groupware. Rather, there will be a "killer infrastructure" -- based on
universal representation of data in XML -- that enables a whole class of
specialized, ad-hoc applications in the same way that the UNIX pipeline
did. 142
Alternatively, to present a Meerkat view on a Web page, you can instead ask Meerkat to render the XML into HTML. This XML-to-HTML transformation is necessary because not all browsers can render XML directly. But we're nearing the end of that era. Internet Explorer can already do it. So can the new Mozilla. 143
RSS is widely regarded as one of the more successful applications of XML. One reason, undoubtedly, is that it's a very simple application of XML. I've focused here on tools that automate the creation and use of RSS channels but, in truth, these tools are optional. Here's an item from my own channel: 144
<item> <title> Talk | MathML </title> <link>http://www.byte.com/nntp/applications?comment_id=7158#thread</link> <description> There appears to be strong progress on the MathML front. The w3c working draft (version 2) is in last call, and it is one of more beautifully written documents of its type that I've ever seen. </description> </item>
As with HTML itself, RSS is easily written by hand. That makes it equally
easy to create tools that transform a variety of other formats into RSS.
Unlike HTML, RSS content can be parsed in a simple and reliable way by
any XML-aware scripting language. That makes it easy to create tools, like
Meerkat, that capture, organize, and enhance RSS flows. 145
The value of the RSS network depends, of course, on the nature and quality
of news flowing through it. In the "technology/computer/geek" community
where RSS evolved, it has become a powerful, well-established, and comprehensive
system for focusing attention on leading-edge developments. Tools like
Manila and Meerkat are rapidly evolving in ways that can bring the benefits
of that system to other communities in need of them, including many scientific
communities. 146
Information overload is a severe problem, and there isn't a single best solution. Weblogs syndicated on the RSS network are no more inherently immune to signal degradation than the Usenet was. XML, in and of itself, doesn't change anything either. What is new, and hopeful, is the notion of a standard format for content syndication. That standard is enabling a new class of information-refinement tools. These tools in turn enable people to search, select, annotate, and reorganize the Web's chaotic flow more easily and more effectively than is otherwise possible. 147
For scientific publishing, there isn't yet an acceptable alternative
to TeX/LaTeX, Word, and FrameMaker. But better solutions are in view, and
they all revolve around standard representation of content in XML. Admittedly,
while the publishing industry has embraced XML in principle as the universal
format for content, there is not yet in practice much writing of XML. When
Web Review (http://www.webreview.com/)
asked
its audience of Web-savvy authors and developers how many were writing
XML, more than half responded "Don't know where to begin," and only 15%
said "Use regularly" (http://webreview.com/wr/pub/2000/06/23/poll/results.html).
148
Few could argue against the inherent benefits of an XML-aware writing
tool. Consider, for example, why TeX is popular. Math typesetting is part
of the reason, but TeX's ability to transform bibliographic markup into
the various formats required by journals is another key strength. 149
Who wouldn't want a WYSIWYG XML editor that can: 150
work interactively with text, equations, and illustrations 151
understand and enforce required formats 152
guarantee easy and automatic repurposing of content 153
work with material that's always editable, yet always Web-ready 154
MS Word doesn't do these things yet, but Microsoft's June 2000 announcement
of its XML-based ".NET platorm" (http://www.microsoft.com/presspass/topics/f2k/presskit.asp)
suggests that Word inevitably will. Meanwhile, other vendors are charging
ahead. In 1999, SoftQuad (http://www.softquad.com/)
broke new ground with the first affordable WYSIWYG XML editor, XMetaL.
Previously, the market for such tools was dominated by multi-thousand-dollar
SGML tools, retrofitted with XML capability, from companies such as ArborText
(http://www.arbortext.com) and Inso
(http://www.inso.com). XMetaL, a $500 Window desktop application, delivers
many of the benefits of the high-end tools. 155
In XMetaL's WYSIWYG mode, you write as with any word processor. Display
of the XML content is controlled by a CSS stylesheet. Everything you write
in XMetaL is also validated -- interactively -- against a DTD (document
type definition). Given a DTD that describes the elements that can occur
in a scientific paper, and the sequence and patterns in which these elements
can occur, XMetaL helps you to create a conforming document, prompting
with the elements that are valid in a given context, much as a programmer's
editor might prompt for the arguments that it is legal to pass to a function.
156
Like the new generation of browsers (MSIE 5, Mozilla), XMetaL is also
a toolkit for developing content-oriented applications. It provides a W3C
Document Object Model (DOM) interface to the content that it manages, and
it wraps a universal scripting interface around that DOM. Because XMetaL
is an ActiveX scripting host, scripts can be written in any compliant scripting
language including VBScript, JavaScript, Perl, or Python. Such scripts
can be used, among other things, to create "wizards" that help users write
to DTD-prescribed formats. And this is the crucial point. A DTD that defines
bibliographies for scientific papers is, by itself, just a passive set
of rules to be learned and followed. People won't embrace XML-oriented
writing tools if they're expected to replace one set of passive rules for
another. What people will embrace are tools that help them enact required
protocols. Bibliographic citation is just one example of such a protocol.
Understood properly, virtually every act of written communication -- a
software bug report, a comment on a draft of a paper, an email message
requesting action on a certain item by a certain date -- is located, conceptually,
within a rule-based protocol. 157
The future of Internet-based collaboration depends, to a very great
extent, on the ability of software to embody these protocols. In this regard,
XML's role as a universal storage and exchange format is only half of the
story. Equally vital is its ability to express, and enforce, the rules
of engagement that govern all collaboration. It can't meet that objective,
though, until it's woven into the fabric of everyday life. Structured writing
can't, and won't, continue to be a specialized activity. It needs to flow
automatically from normal use of the frontline applications -- word processors,
email clients -- that capture most of what we say, and produce most of
what we know. 158
The bad news is that infrastructure change on this order of magnitude
can't happen quickly. The good news, though, is that there is now general
consensus as to how to accomplish the change, and much demonstrable recent
progress. To illustrate that concretely, let's consider how two datatypes
central to scientific collaboration -- equations and charts -- are being
woven into the fabric of the emerging two-way Web. 159
snip ends